- 发布日期:2025-08-10 10:53 点击次数:67
3月1日,DeepSeek在知乎上发表题为《DeepSeek-V3/R1推理系统概览》的著述,全面揭晓V3/R1推理系统背后的要道神秘。

据著述先容,DeepSeek-V3/R1推理系统的优化缠绵是更大的婉曲、更低的延伸。为了已毕这两个缠绵,DeepSeek使用了大范围跨节点大众并行(Expert Parallelism/EP)的模范,并通过一系列技妙策谋,最猛进度地优化了大模子推理系统,已毕了惊东说念主的性能和成果。
具体而言,在更大的婉曲的方面,大范围跨节点大众并行能够使得batch size(批尺寸)大大增多,从而进步GPU矩阵乘法的成果,进步婉曲。
batch size在深度学习中是一个相配迫切的超参数,指模子在测验历程中每次使用的数据量大小。它决定了每次模子更新时使用的测验样本数目,挪动batch size不错影响模子的测验速率、内存奢华以及模子权重的更新花式。
在更低的延伸方面,大范围跨节点大众并诓骗得大众散布在不同的GPU上,每个GPU只需要策划很少的大众(因此更少的访存需求),从而裁汰延伸。
然而,由于大范围跨节点大众并行会大幅增多系统的复杂性,带来了跨节点通讯、多节点数据并行、负载平衡等挑战,因此DeepSeek在著述中也重心推崇了使用大范围跨节点大众并行增大batch size的同期,如何遮掩传输的耗时,如何进行负载平衡。
具体来看,DeepSeek团队主要通过范围化跨节点大众并行、双批次重迭计谋、最优负载平衡等花式,最大化资源利用率,保证高性能和稳健性。
值得留心的是,著述还露馅了DeepSeek的表面资本和利润率等要道信息。据先容,DeepSeek V3和R1的统共处事均使用英伟达的H800GPU,由于白昼的处事负荷高,晚上的处事负荷低,DeepSeek已毕了一套机制,在白昼负荷高的时候,用统共节点部署推理处事。晚上负荷低的时候,减少推理节点,以用来作念估计和测验。
通落伍辰上的资本铁心,DeepSeek暗示DeepSeek V3和R1推理处事占用节点总数,峰值占用为278个节点,平均占用226.75个节点(每个节点为8个H800GPU)。假设GPU租借资本为2好意思元/小时,总资本为87072好意思元/天;若是统共tokens沿途按照DeepSeek R1的订价策划,表面上一天的总收入为562027好意思元/天,资本利润率为545%。
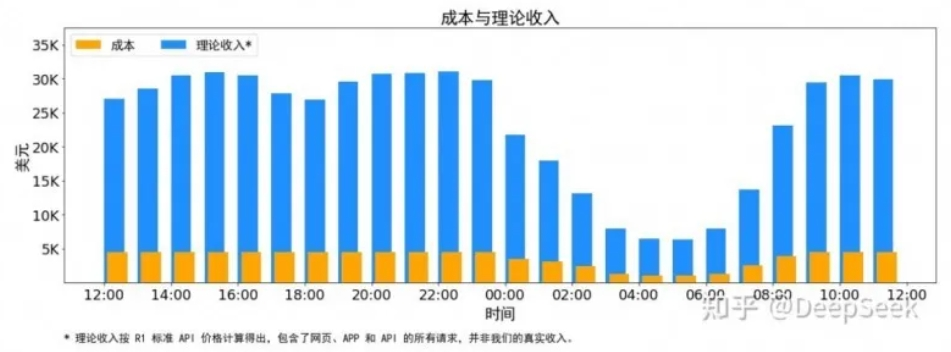
不外,DeepSeek也强调,实质上的收入粗略并莫得那么多,因为V3的订价相较于R1要更低,另外夜间还会有扣头。记者留心到,2月26日,DeepSeek在其API洞开平台发布错峰优惠当作告知。把柄告知,北京时辰逐日00:30-08:30为错峰时段,API调用价钱大幅下调,其中DeepSeek-V3降至原价的50%,DeepSeek-R1降至25%。DeepSeek饱读吹用户在该时段调用,享受更经济更流通的处事体验。
上周五(2月21日),DeepSeek告示联络五天开源五大软件库。2月25日DeepSeek采选了先在GitHub上线,然后再在官推发布上新告知。该公司25日告示将DeepEP向公众洞开。在告示后的约20分钟内,DeepEP已在GitHub、微软(MSFT.US)等平台上取得进步1000个Star储藏。
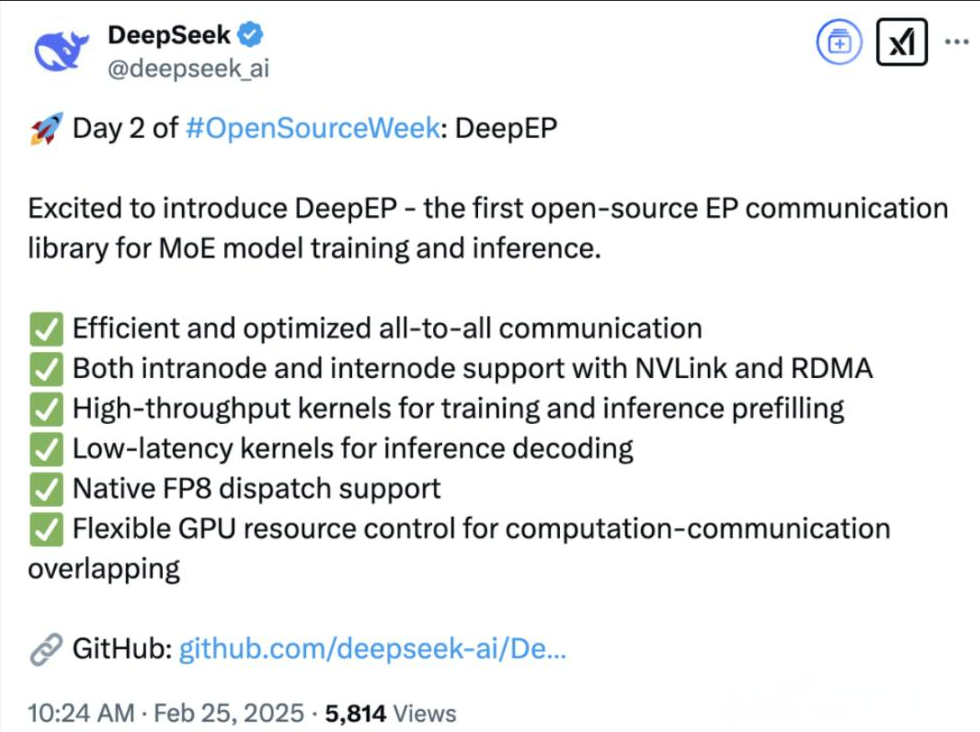
据悉,DeepEP是MoE模子测验和推理的ExpertParallelism通讯基础,可已毕高效优化的全到全通讯,以因循包括FP8在内的低精度策划,适用于当代高性能策划。DeepEP还针对从NVLink到RDMA的非对称带宽转发场景进行了深度优化,不仅提供高婉曲量,还因循流式多科罚器数目铁心,从而在测验和推理任务中已毕高婉曲量性能。
逐日经济新闻空洞自公开信息开云官网切尔西赞助商
- 开云官网切尔西赞助商2025年1月4日安徽六安市裕安区紫竹林农家具批发市集价钱行情-开云平台皇马赞助商「中国」官方入口2026-03-01
- 开云官网切尔西赞助商共计派现总数为53.97亿元-开云平台皇马赞助商「中国」官方入口2026-02-14
- 开云官网切尔西赞助商消耗者张**(手机尾号 0287-开云平台皇马赞助商「中国」官方入口2026-02-12
- 开云官网切尔西赞助商区别占当期泄露金额的0.59%、5.22%-开云平台皇马赞助商「中国」官方入口2026-02-10
- 开云官网切尔西赞助商深证成指跌0.95%-开云平台皇马赞助商「中国」官方入口2026-01-30
- 开云官网切尔西赞助商她带给了我一个凶讯!李林在一次战斗中-开云平台皇马赞助商「中国」官方入口2026-01-20